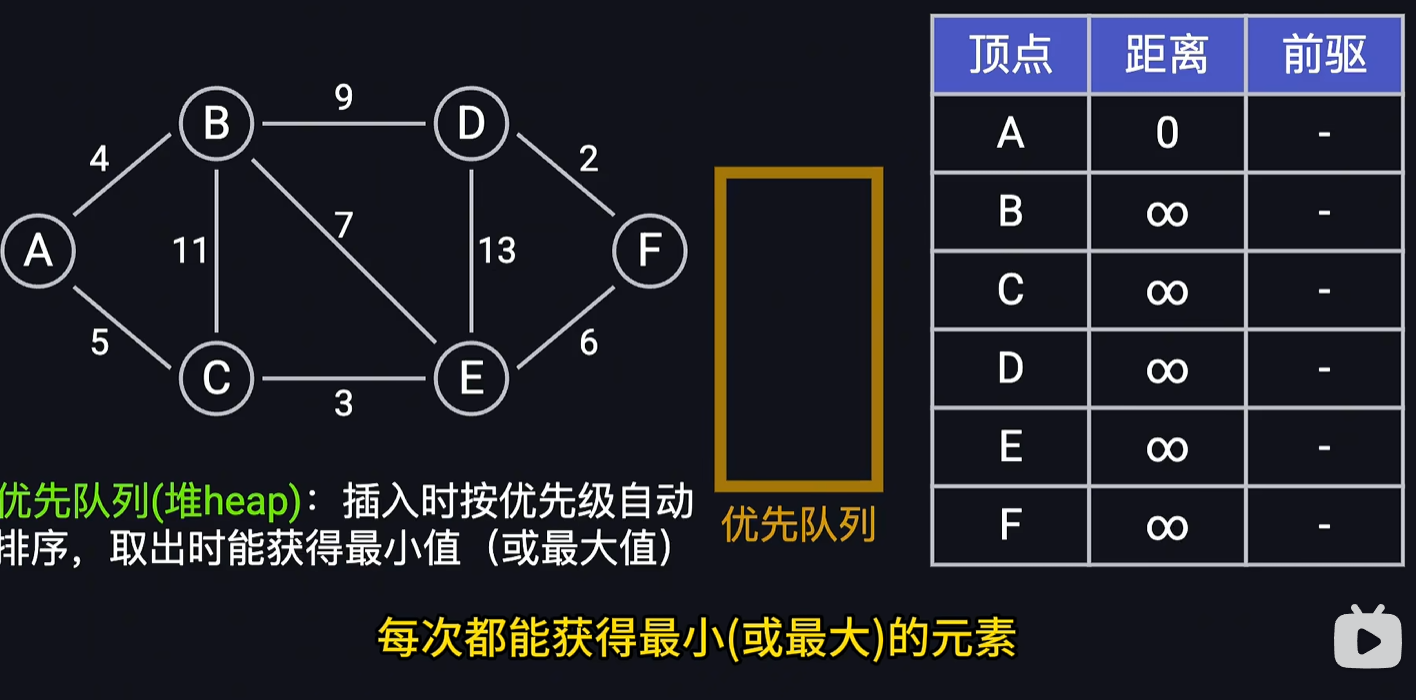
structEdge { int f, t, cost; bool used; Edge(int f, int t, int c) : f(f), t(t), cost(c), used(false) {} booloperator<(const Edge& e) { returnthis->cost < e.cost; } };
classSet { public: std::vector<int> parent;
Set(int n) : parent(n + 1) { for (int i = 0; i < parent.size(); i++) { parent[i] = i; } }
intfind(int index){ int root = parent[index]; while (root != parent[root]) { root = parent[root]; } return root; }
voidunite(int x, int y){ int xRoot = find(x); int yRoot = find(y); if (xRoot == yRoot) return; parent[yRoot] = xRoot; }
boolsame(int x, int y){ returnfind(x) == find(y); } };
intmain(){ int n, m; std::cin >> n >> m;
std::vector<Edge> edges;
for (int i = 0; i < m; i++) { int u, v, w; std::cin >> u >> v >> w; edges.push_back({ u, v, w }); }
std::sort(edges.begin(), edges.end());
std::vector<std::vector<std::pair<int, int>>> graph(n + 1); Set set(n); int count = 0, total = 0; for (auto& edge : edges) { if (!set.same(edge.f, edge.t)) { set.unite(edge.f, edge.t); ++count; total += edge.cost; edge.used = true; graph[edge.f].emplace_back(edge.t, edge.cost); graph[edge.t].emplace_back(edge.f, edge.cost); if (count == n - 1) { break; } } }
std::unordered_set<int> roots; for (int i = 1; i <= n; i++) { roots.insert(set.find(i)); } if (roots.size() > 1) { std::cout << "NO MST\n" << roots.size(); return0; }
return0; }
基于最小生成树, 我们得到了一个新图, 在代码里是graph变量.
仅包含了最小生成树的路径.
在这个graph中, 用DFS寻找从u到v的路径上的最大边权和次大边权.
boolDFS(int u, int target, int fa, int curr_max1, int curr_max2, int& max1, int& max2, const std::vector<std::vector<std::pair<int, int>>>& graph){ if (u == target) { max1 = curr_max1; max2 = curr_max2; returntrue; } for (auto& e : graph[u]) { int v = e.first; int w = e.second; if (v == fa) continue; int new_max1 = curr_max1, new_max2 = curr_max2; if (w > new_max1) { new_max2 = new_max1; new_max1 = w; } elseif (w < new_max1 && w > new_max2) { new_max2 = w; } if (DFS(v, target, u, new_max1, new_max2, max1, max2, graph)) { returntrue; } } returnfalse; }
bool unique = true; int second = int(static_cast<unsignedint>(-1) >> 1); for (auto& edge : edges) { if (!edge.used) { int u = edge.f, v = edge.t, w = edge.cost; int max1, max2; get_max_edge(u, v, max1, max2, graph); if (unique && w == max1) { unique = false; } if (max1 != -1 && w > max1) { second = std::min(second, total - max1 + w); } if (max2 != -1 && w > max2) { second = std::min(second, total - max2 + w); } } }
根据我们前面说的, w == 最大边权的时候, MST不唯一.
对second的更新非常关键, 但我个人想不清楚这玩意,
想了半天...只能说就是这样写的吧.
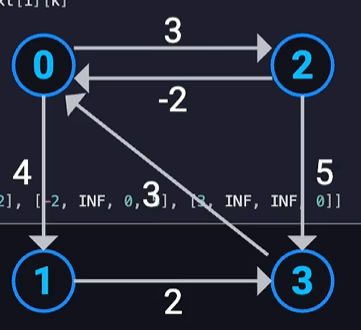
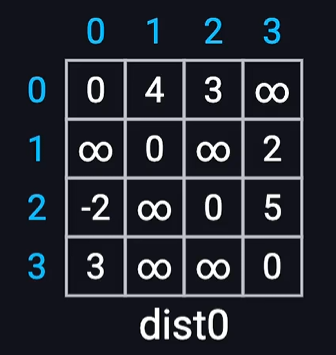
for (int i = 0; i < M; i++) { int u, v, l; std::cin >> u >> v >> l; if (dist[u][v] > l) { dist[u][v] = l; dist[v][u] = l; next[u][v] = v; next[v][u] = u; } }
for (int i = 0; i <= N; i++) { dist[i][i] = 0; next[i][i] = i; }
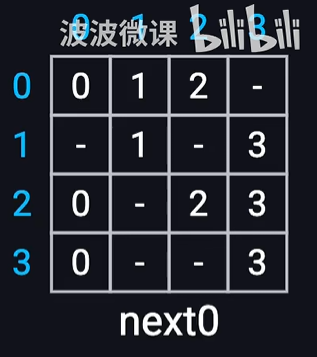
for (int k = 1; k <= N; k++) { for (int i = 1; i <= N; i++) { for (int j = 1; j <= N; j++) { if (dist[i][k] != INTMAX && dist[k][j] != INTMAX) { if (dist[i][j] > dist[i][k] + dist[k][j]) { dist[i][j] = dist[i][k] + dist[k][j]; next[i][j] = next[i][k]; } } } } }
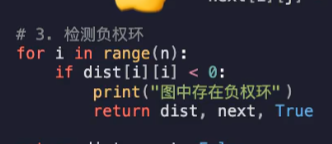
std::vector<int> result(N + 1, -INTMAX); int minDist = INTMAX, index = 0; for (int i = 1; i <= N; i++) { for (int j = 1; j <= N; j++) { if (dist[i][j] == INTMAX) { std::cout << 0; return0; } result[i] = std::max(result[i], dist[i][j]); } if (result[i] < minDist) { minDist = result[i]; index = i; } }
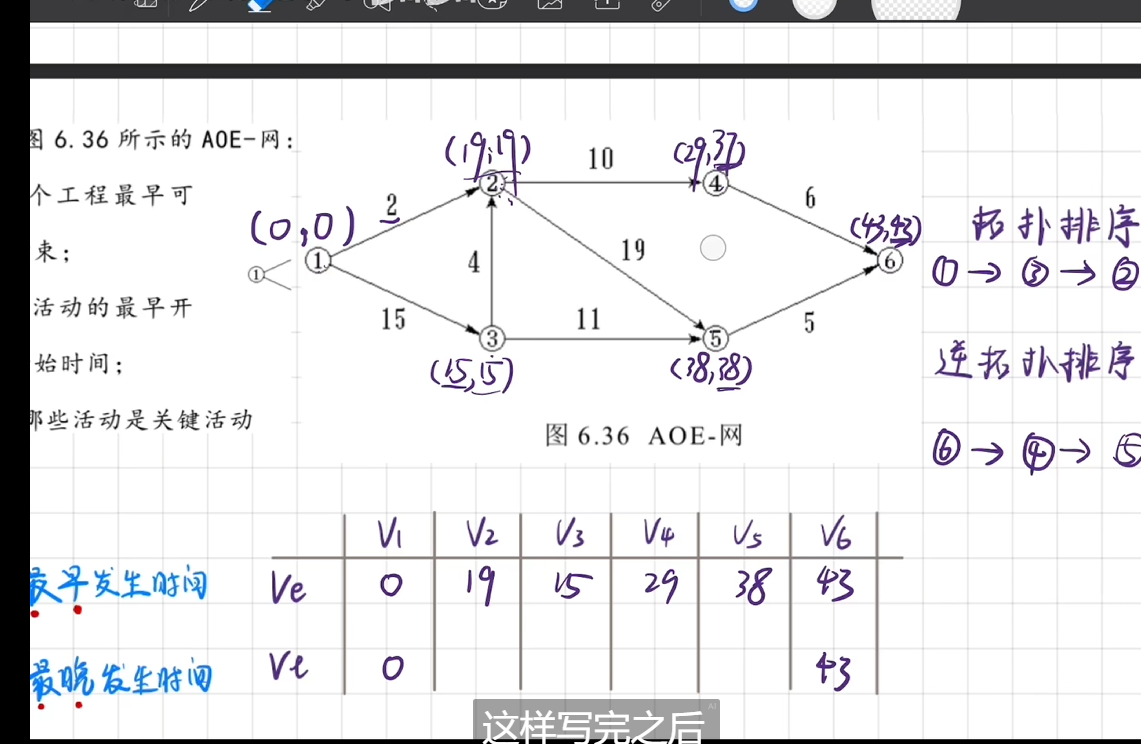
std::vector<int> ve(N + 1, 0); for (int i = 0; i < topo.size(); i++) { for (auto& p : graph[topo[i]]) { int node = p.first; int len = p.second; if (ve[node] < ve[topo[i]] + len) { ve[node] = ve[topo[i]] + len; } } } std::vector<int> vl(N + 1, ve[topo[N - 1]]); for (int i = topo.size()-1; i >= 0; i--) { for (auto& p : graph[topo[i]]) { int node = p.first; int len = p.second; if (vl[topo[i]] > vl[node] - len) { vl[topo[i]] = vl[node] - len; } } }
std::cout << ve[topo[N - 1]] << "\n"; for (int i = 0; i < topo.size(); i++) { for (auto& p : graph[topo[i]]) { int node = p.first; int len = p.second; if (vl[node] - ve[topo[i]] == len) { std::cout << topo[i] << "->" << node << "\n"; } } }
.jpg)